1. What the heck is NodeMCU
Simply It's a cheap arduino like micro-controller with some new built in features. OK what are those new features ? Mainly it's all about
wifi. Yes It has a built in wifi module, the latest NodeMCU devkit use
ESP8266 SMT Module - ESP-12E (main chip) which has 4MB of flash memory and tons of IO pins with
Lua Firmware(I'll explain about this on 2nd topic NodeMCU Firmware Features).
Figure1.1 - ESP8266 SMT Module - ESP-12E Module
Now you know about the main chip, heart of the NodeMCU devkit. So what is this NodeMCU devkit. You can think it as like this, Its a simplified wrapper for developers who wants to rapidly prototype and write and push their code quick. In other word it's a
breakout board (It takes a single electrical component and make's it easy to use).
Figure1.2 - NodeMCU DEVKIT V1.0
It's a beautiful little circuit board isn't it. :) Ok according to Figure 1.2 mainly you can see there's a micro usb port + IO pins coming out of the board. Time to explorer some abilities of this piece of hardware. I mentioned two words "Lua Firmware" which lives in the main module (ESP8266 SMT Module - ESP-12E Module) . We'll discuss some features that Lua Firmware has.
2. NodeMCU Firmware
NodeMCU firmware is a Lua based firmware for the main chip (ESP8266 SMT Module - ESP-12E Module) according to
nodemcu-firmware project more than 98% of the code is written in C and have used a small Lua interface to
simplified the development. Finally :) Cool right !. This firmware helps to work with wifi, serial, gpio communications etc... Lets see what are the main cool features support by this firmware.
- Supports 40+ modules (APIs).
- WIFI - what keeps all the things connected together.
- GPIO - manipulate IO pins (digital, analog).
- HTTP - www open the connection to the world (clients, servers).
- MQQT - best for IoT communication.
- WEBSOCKET - now most of the the things are real-time (widely support communication).
- JSON - manipulating JSON data (encoding, decoding).
- FILE - Remember 4MB of space :) (read, write).
- + More ...
- Easy Peasy API.
- Lua based API.
- Really good documentation.
- Real-time line by line code testing capability (They have provided a REPL (read, evaluate, print, loop) tool we'll look in to that in 5th topic Playing time with NodeMCU) .
- Asynchronous event-driven programming model. (Which makes more scene :) )
- Custom firmware builds
- This is a cool feature, we can build the latest firmware easily and push it to the NodeMCU.
- We can build the firmware with floating point support or only integer support. (integer based firmware takes less memory).
- We'll dig in to above features in next topic Building latest and custom firmware.
3. Building latest and custom firmware
Now we a have overall idea about what NodeMCU is and what it can do. Now its time do something in action.
- Docker (Engine & Client) - How to Install docker to your system (Windows/Linux)
As I mentioned in "2nd topic NodeMCU Firmware" you can build any custom firmware you want and install it to devkit via the micro USB. Lets see how it's done easily. In this topic we'll focus only the firmware building process (Dont worry it's super easy). There are 3 ways to build the firmware
Via Cloud build service (Super EASY)
From this service it's supper easy to get the firmware build. We can easily customize the modules and other options through their web interface Figure 3.1. You can select which modules need to activate or enable from the firmware so you can save more memory for your code.
Figure 3.1 - Cloud Build Module Customization
After few minutes you will get a mail with 2 download links to firmware build files
- nodemcu-master-10-modules-date+time-float.bin
- nodemcu-master-10-modules-date+time-integer.bin
As I mentioned you can either use float or integer firmware (Integer takes less space) What the heck you have 4MB flash use float bin :)
Via Docker image
This is my favorite way of building the firmware. May be because of I'm in love with docker. Anyway if you are planing to use the firmware for production it's good to rebuild it using the cloud build service with custom modules. This method will build whole master/dev branch with all 40+ modules. Time to execute some instructions.
- First things first - Pull the docker container of nodemcu-build
- docker pull marcelstoer/nodemcu-build
- Clone the nodemcu-firmware repository
- git clone https://github.com/nodemcu/nodemcu-firmware.git
- Navigate to nodemcu-firmware project folder and execute the docker command to buid
- docker run --rm -ti -v `pwd`:/opt/nodemcu-firmware marcelstoer/nodemcu-build
- After 2-3 minutes you can find the build files inside bin folder. There can be several bin files, you only need to care about integer/float bin files
Next topic I will discuss how to push these firmware binaries to NodeMCU module.
4. Update the firmware
Now we have the firmware binary file. It's time to update the NodeMCU with latest module features. Man I love this part = )
Now I'm gonna introduce a tool called
esptool which helps to upload the firmware to nodemcu really easily. Lets see what are the steps you need to follow
- Clone the esptool project.
- git clone https://github.com/espressif/esptool
- You can find a executable python file "esptool.py" inside esptool folder.
- Plug your NodeMCU via micro USB.
- Execute 1st command to erase the whole NodeMCU firmware. (You need to provide the connected USB port)
- ./esptool.py --port /dev/ttyUSB0 erase_flash (Linux)
- python esptool.py --port COM1 erase_flash (Windows)

- Note: erase command will erase all Lua scripts that have uploaded.
- It will take few seconds to complete the whole erasing task.
- Now you have a completely empty and useless NodeMCU module :( don't worry now is the time to give completely new BRAIN.
- Note: Do you know NodeMCU has a bug :) Ok don't worry there's a solution and small fix to it. The bug is, when you erase the whole flash and push our firmware build to NodeMCU it wont work. For that issue they have created a patch [ Download SDK patch 1.5.4.1 ] (Seems to be a hardware issue in ESP8266 wifi module).
- Brace your self now is the time to upload the firmware with this patch. You need only 2 files
- nodemcu_float_master_xxxxxxxx-xxxx.bin - (NodeMCU firmware)
- esp_init_data_default.bin - (NodeMCU patch file, You can find this file after extracting the ESP8266_NONOS_SDK_V1.5.4.1_patch_20160704.zip)
- Lets execute the command :)
- ./esptool.py --port /dev/ttyUSB0 write_flash 0x00000 ../nodemcu-firmware/bin/nodemcu_float_master_20161116-0032.bin 0x3fc000 ../ESP8266_NONOS_SDK_V1.5.4.1_patch_20160704/esp_init_data_default.bin
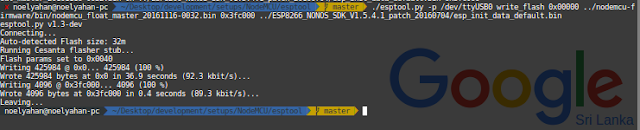
- DONE ! Oh wait we need to test It out :) Next and Final topic will explain the actual power of the NodeMCU.
5. Play time with NodeMCU
Now I'm gonna introduce another tool. Oh don't worry this is the last and best tool that I'm gonna introduce to you . The tool is called
ESPlorer This will help us to push the code inside NodeMCU super duper easily. It's a java app so no need to worry :)
After you download and extract the file from their site. you can start the ESPlorer tool really easily
- If you are a Linux user like me > java -jar ESPlorer.jar
- If you are a Windows user > execute the bat file
- After the application starts you need to select the USB port, Baud rate to 115200 and press open button.
- Some times you may need to click on some buttons at the bottom (Heap, Chip Info, etc..) to open up the connection properly.
- Now it's time to test a typical LED blink app, There's a nice testing blink Lua script in github.
- Copy and paste the code to Scripts section.
- Click on Send to ESP button.
- Suddenly you can see your NodeMCU will blink it's built in LED.
- I'm so HAPPY Now !!
- I almost forgot about wifi. It's super easy now.
- Can you see a small text box on bottom of the right hand side with a send button (That's the miracle button)
- You can easily type a code and evaluate in real time. Lets print out some ip address in station mode
- Copy and paste this code line and look at the result: print(wifi.sta.getip())
- Cool isn't it. Now you have a solid playground to explorer more and more API features in NodeMCU. Hope My Blog Post Was Helpful To You :)
#HappyCoding #SeeYouLater





























{kind=link}
{kind=link}
{kind=link}
{kind=link}